
About Me
I am currently a 2nd-year Master’s student at Tsinghua University  . I received my B.Eng. degree in Computer Science (Yingcai Honors College) from University of Electronic Science and Technology of China
. I received my B.Eng. degree in Computer Science (Yingcai Honors College) from University of Electronic Science and Technology of China  in 2024.
in 2024.
My research interest includes: Image & Video Generation Human-Centric Generation Reinforcement Learning
News
CVPR 2026.AAAI 2026.TPAMI.ICCV 2025.Publications
CoInteract: Physically-Consistent Human-Object Interaction Video Synthesis via Spatially-Structured Co-Generation
Xiangyang Luo*, Xiaozhe Xin*†, Tao Feng, Xu Guo, Meiguang Jin, Junfeng Ma
Paper Page Code

CoInteract introduces a Human-Aware Mixture-of-Experts and Spatially-Structured Co-Generation paradigm for physically-consistent human-object interaction video synthesis, achieving zero-overhead inference while significantly improving structural stability and interaction plausibility.
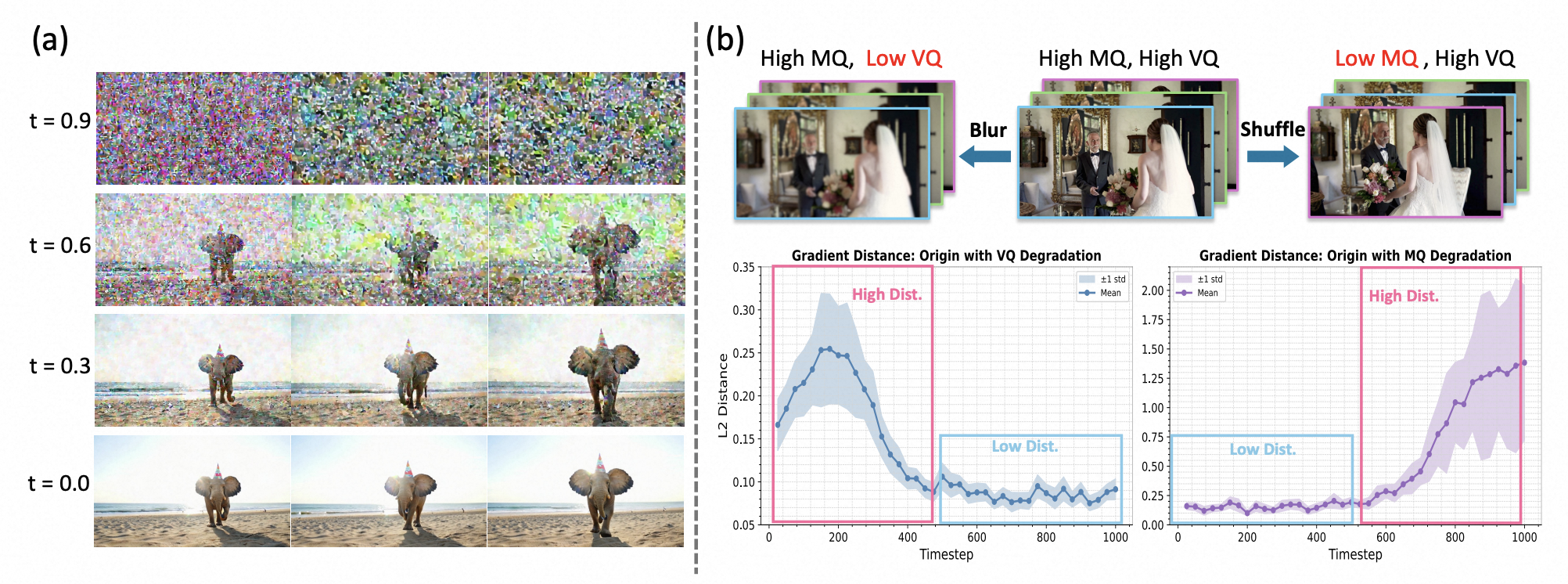
Beyond the Golden Data: Resolving the Motion-Vision Quality Dilemma via Timestep Selective Training
Xiangyang Luo, Qingyu Li, Yuming Li, Guanbo Huang, Yongjie Zhu, Wenyu Qin, Meng Wang, Pengfei Wan, Shao-Lun Huang
Paper
We identify the Motion-Vision Quality Dilemma in video data curation and propose Timestep-aware Quality Decoupling (TQD), which skews the training data sampling distribution across timesteps to decouple motion and visual quality, enabling models trained on imbalanced data to surpass those trained on golden data.
FilmWeaver: Weaving Consistent Multi-Shot Videos with Cache-Guided Autoregressive Diffusion
Xiangyang Luo, Qingyu Li, Xiaokun Liu, Wenyu Qin, Miao Yang, Meng Wang, Pengfei Wan, Di Zhang, Kun Gai, Shao-Lun Huang
Paper Page
FilmWeaver generates consistent multi-shot videos of arbitrary length via an autoregressive diffusion paradigm, enforcing inter-shot consistency with a Shot Cache and intra-shot coherence with a Temporal Cache, and supports applications such as concept injection and video extension.
Human Motion Video Generation: A Survey
Haiwei Xue, Xiangyang Luo, Zhanghao Hu, Xin Zhang, Xunzhi Xiang, Yuqin Dai, Jianzhuang Liu, Minglei Li, Jian Yang, Fei Ma, Changpeng Yang, Zonghong Dai, Fei Richard Yu
Paper Page

This survey provides a comprehensive review of human motion video generation methods, covering the latest techniques, applications, and future directions.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Xiangyang Luo , Ye Zhu†, Yunfei Liu, Lijian Lin, Cong Wan, Zijian Cai, Shao-Lun Huang†, Yu Li
Paper Page Code

CanonSwap decouples motion information from appearance to enable high-fidelity and consistent video face swapping.
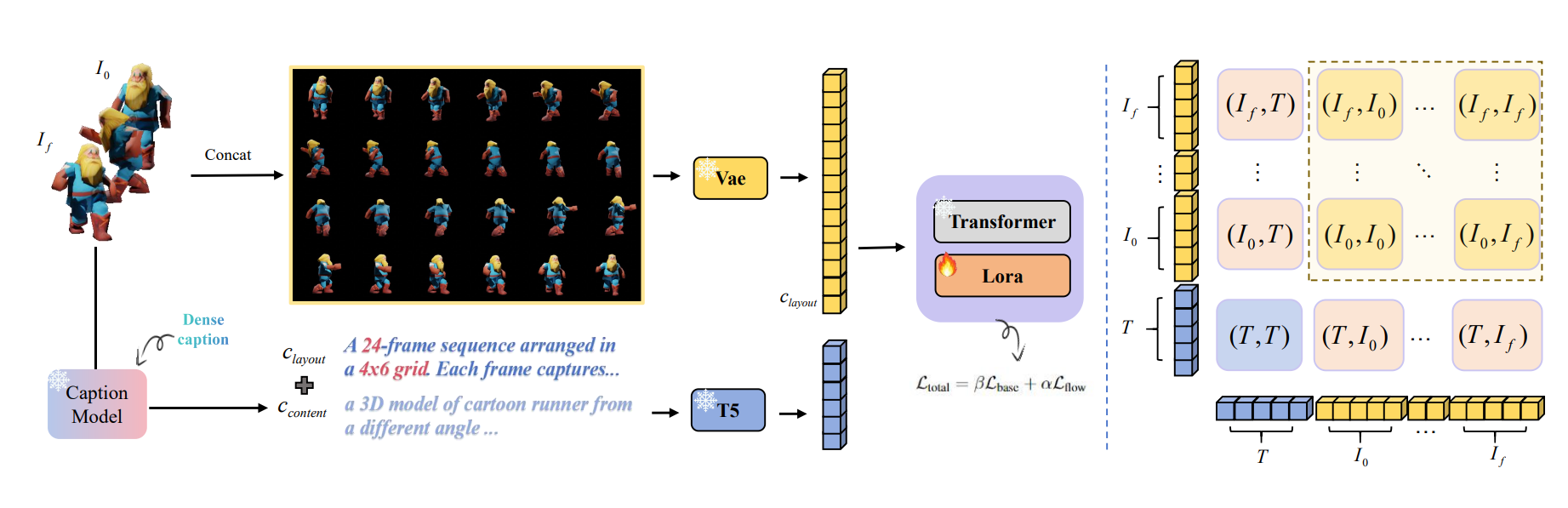
Grid: Omni Visual Generation
Cong Wan*, Xiangyang Luo*, Hao Luo, Zijian Cai, Yiren Song, Yunlong Zhao, Yifan Bai, Fan Wang, Yuhang He, Yihong Gong
Paper Code
GRID is an omni-visual generation framework that reformulates temporal tasks like video into grid layouts, enabling a single powerful image model to efficiently handle image, video, and 3D generation.

CodeSwap: Symmetrically Face Swapping Based on Prior Codebook
Xiangyang Luo, Xin Zhang, Yifan Xie, Xinyi Tong, Weijiang Yu, Heng Chang, Fei Ma†, Fei Richard Yu
Paper
CodeSwap achieves high-fidelity face swapping by symmetrically manipulating codes within a pre-trained, high-quality facial codebook.